|
3D Head Tracking
Automatic head pose alignment in 3D The automated FACS coding described above aligned faces in the 2D plane. Spontaneous behavior, however, can contain a considerable amount of out-of-plane head rotation. The accuracy of automated FACS coding may be considerably improved by aligning faces in 3D. Moreover, head pose information is an important component of FACS. Automated head pose tracking will speed up one of the more time consuming components of FACS coding, plus provide information about head movement dynamics that was previously unavailable through hand coding. The feasibility study in 2001 showed that 3D alignment and rotation to frontal views is a viable approach to recognizing facial actions in the presence of out-of-plane head rotations. At the time of the feasibility study, head pose estimates were obtained from a set of eight hand-marked feature points. As part of our NSF funded research in the past 18 months, we developed an algorithm for fully automatic head pose estimation (Marks, Hershey, Roddey, & Movellan, 2003). See Figure 1.
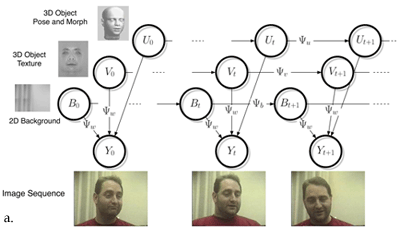
The system is a generative model, called G-flow, which tracks nonrigid objects in 3D from 2D video data. This problem, which is crucial to many potential applications in computer vision, is challenging because of the observed variation in 2D images over time caused by a variety of sources in the world, such as rigid motion, nonrigid motion, changes in lighting source, and changes in brightness as surfaces change orientation or bend with respect to the luminance source. State of the art computer vision methods for face tracking in 3D simultaneously estimate rigid motion (head pose) and nonrigid motion (facial expression) using optic flow (e.g. Torresani et al., 2001; Brand, 2001). Optic Flow-based tracking methods such as these make few assumptions about the appearance of the object being tracked, but they require good knowledge of the current location of the object and have a tendency to drift as errors accumulate. Model initialization and recovery from drift are open questions that are typically handled using hieuristic methods.G-flow incorporates template-based tracking with flow-based tracking in a generative model framework. See Figure 2.
In contrast to flow-based approaches, template based approaches are more robust to position uncertainty, but require good knowledge of the graylevel appearance of the object. Templates are less tolerant to image variations (e.g. due to changes in pose, illumination, or facial expression), and typically require dynamic updating of the templates and periodic re-registration, which again are typically performed using hieuristics. The inference algorithm in G-flow unifies optic-flow and template-based tracking methods, dynamically adjusting the relative weights of each in a principled manner. Optimal inference is performed efficiently by using a bank of kalman filters for texture whose parameters are updated by an optic-flow like algorithm. This inference algorithm promises principled solutions to the issues of model initialization, recovery from drift, and dynamic updating of templates. In G-flow, motion estimates are constrained by a 3D face model that can undergo nonrigid deformation defined by a set of morph basis functions. See Figure 3
At present, the system requires calibration to estimate the face geometry of each individual and his/her morph basis functions. Our future work is to learn a set of person-independent morph basis functions that will enable Gflow to operate in a person-independent way. These will be learned from a dataset of face deformations in 3D. |