
Offering RESEARCHERS a Baby's-Eye-View
In the Machine Perception Laboratory, we try to understand Human Cognition by characterizing accurately the problems people solve in an uncertain world. We have found this approach, called probabalistic functionalism, very fruitful in advancing our understanding of the nature of intelligence.
 |
 |
 |
In the BEV Project, we set out to characterize what visual information was available to infants, and what could be learned automatically, without any external teaching signal. Following the hypothesis of John Watson, we used detection of auditory social contingencies to provide a weak indication as to whether or not a person was visible in BEV's field of view. Even with this noisy intenerally generated label, we were able to show that BEV could learn, from very little experience, to locate people in her visual field.
 |
 |
 |
The BEV1 Dataset is a resource for those who wish to begin exploring the visual world available to infants and robots, and seeking to answer questions about the wide array of representations learnable without any teacher, and without any informative preexisting knowledge of the world.
 |
 |
 |
Download
The data below can be downloaded freely for scientific, non-commercial uses. If you publish work based on these data, please cite the article where this collection of images and their internarlly generated labels are first described:
- Nicholas J. Butko, Ian R. Fasel, & Javier R. Movellan (2006) "Learning about Humans During the First 6 Minutes of Life," Proceedings of the 5th Internation Conference on Development and Learning (ICDL'06) [PDF].
There are three versions of the BEV1 Dataset available for download:
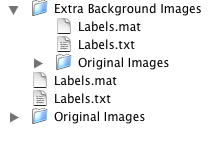
- BEV1Lite (34MB): All original images, as described in (Butko, Fasel, & Movellan 2006).
- BEV1Full (44MB): Original images, plus extra background images
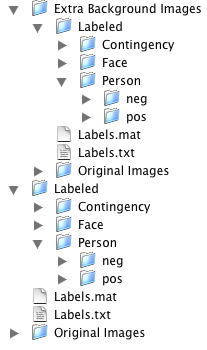
- BEV1Plus (177MB): Original and Extra Background images, with separate folders for each class label (contains four copies of each image).
What you get:
| BEV1Lite | BEV1Full | BEV1Plus |
 |
 |
 |
Format
The directories called "Original Images" contain original data collected and automatically labeled by BEV. The image names are generally of the format "BEV1Pos00001.jpg" indicating that this was the first positive-labeled image saved by BEV.
As indicated in our paper, these labels are only somewhat reliable. For this reason, we have also provided two additional sets of human-generated labels: "Face" and "Person." In our experiments, these labels were only used in evaluation, not training.
The files "Labels.txt" and "Labels.mat" contain these extra labels. "Labels.txt" is of the form
"filename originalContingencyLabel faceLabel personLabel"
where filename is a string of characters and the labels are -1 or 1, indicating negative and positive examples:

"Labels.mat" is a Matlab7 file, containing an array of structures called "BEV1Labels." Each structure element has "name," "contingency," "face," and "person" fields with identical values to those in "Labels.txt".
The Full and Plus datasets contain over 1000 extra background images. In our original data collection, we had an artificial bias toward positive images because we only saved on auditory events, which happen much more regularly when someone is responding than when nobody is responding. While we did not use these extra background images in our experiments, you may wish to use them in yours. If so, note that the Labels files for the original images and the extra background images are different, as are the filename conventions: images in the Extra Background set have names like "BEV1ExtraBGPos00001.jpg".
In the Plus dataset only, in addition to the normal image directories, the positive and negative examples in each label class are segregated into different directories. This is desirable if you don't want to parse a file like "Labels.txt," but would prefer just to use all files in a given directory as positives, and all files in another directory as negatives. Since there are three sets of labels, there are three copies of each image in addition to the original. Hence the "Plus" dataset is much bigger than the other two.