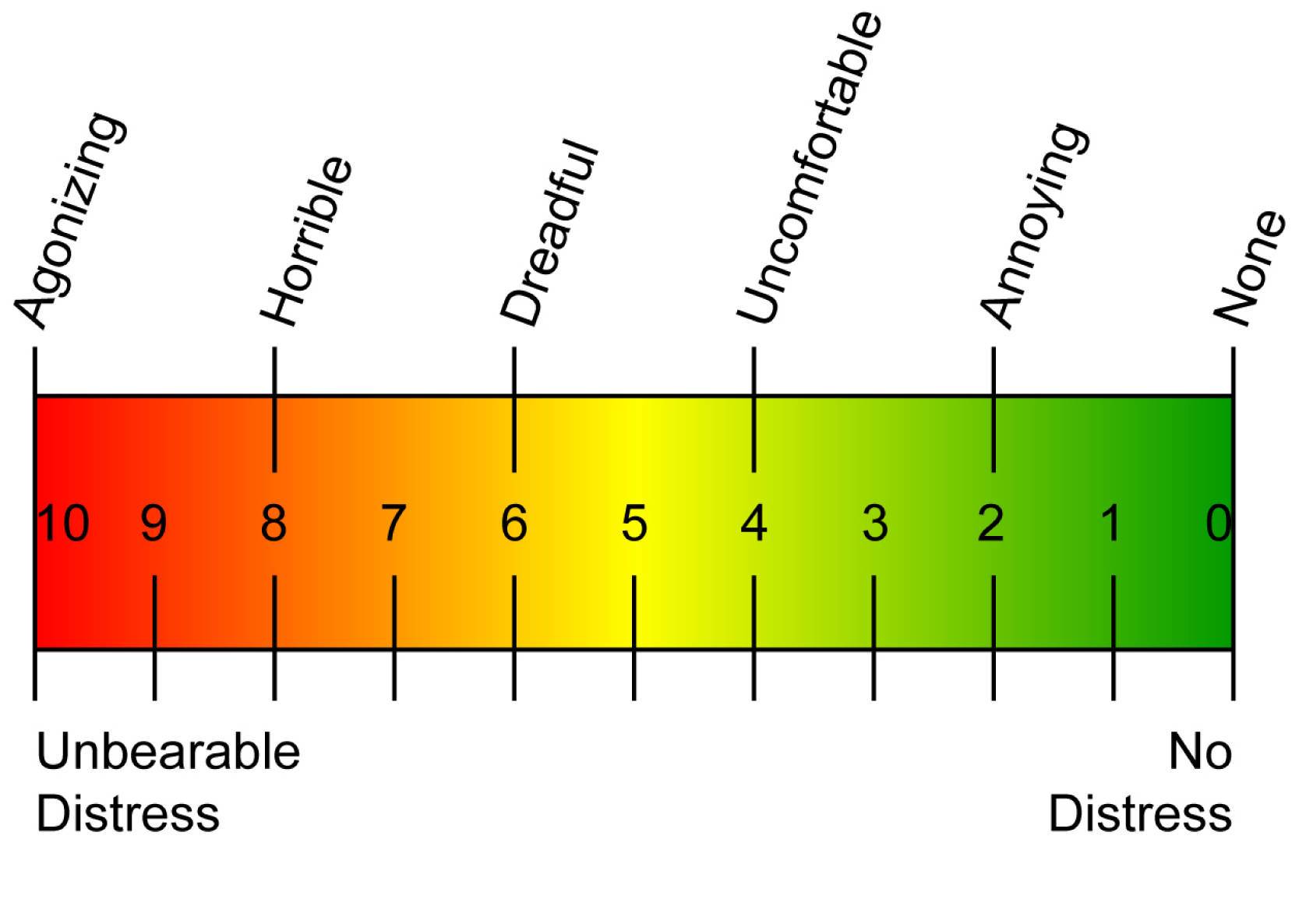
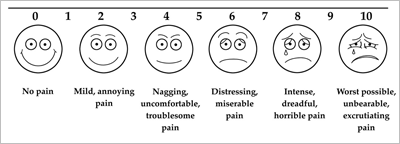
Project Synopsis: Pain signal is difficult to examine and considered critical in clinical applications. An example scenario is that a doctor can regulate medications for his patient depending on how much pain he/she is going through. Currently pain is measured by either clinical interview or asking patient to report thier pain on a scale of 0-10, refered to as visual analog scales (VAS) (shown below). These self-report measures suffer from subjective differences and often invovlve patient idiosyncrasies. Hence the focus of this work is on designing automated systems to measure pain in an objective manner. This is achieved by training an automated state-of-the-art computer vision algorithm for this task.
Related publication: Sikka, K., Dhall, A., & Bartlett, M. (2013). Weakly Supervised Pain Localization using Multiple Instance Learning, IEEE International Conference on Automatic Face and Gesture Recognition, 2013. (Oral Presentation) [PDF]
| |
|
|---|
Challenges: Identifying pain is a challenging task owing to it's spontaneous nature and the variablity associated with the signal. Our test-bench consists of videos of patients undergoing shoulder pain (bursitis, tendonitis, subluxation, rotator cuff injuries etc.) in the recently introduced UNBC-McMaster Pain dataset[1]. The problem is further complicated by the fact that we are only using video-level labellings, that inform us about whether there is pain/no-pain in entire sequence without any information about the specific frames containing pain expression. These labelling are incomplete and introduces ambiguity since not all frames in a pain-video belong to pain. Rather these videos contain repeated phases of pain activity followed by neutral (no-pain) phase. Thus the algorithm needs to tackle three aspects.
1. Ambuguity introduced by incomplete labels
2. Incoporate motion information.
3. Temporally segments frames containing pain and no-pain.
Our Approach: There are two core ideas in this work. First we propose to use weakly-supervised learning approaches that can handle ambiguity much better than traditional Machine Learning methods. Secondly we represent a video as a bag of multiple sequences (shown in Fig.3). We refer to this as multiple segment representation and it's a novel way for representing videos for expression recognition. This representation addresses the problem of including temporal dynamics and handling the variability of pain expression in videos. This representation is build on discriminative Bag of Words architecture we proposed for facial expression recognition in ECCV'12 Workshop in Faces[2]. We refer to our algorithm as Multiple Segment based Multiple Instance Learning
 |
|---|
Each video represented as a bag are trained using MilBoost learning algorithm[3]. This learned model can then be used for predicting the probability of pain in a segment, video and each frame. The probabilty of each segment and a video is predicted as shown in Fig.4. It is interesting to note that the algorithm is intuitive in saying that the probability of a video being in pain is a maxima over each of it's segments.
 |
|---|
Results: We compared our algorithm with previous state-of-the-art algorithm proposed by Lucey et.al in [4]. For highlighting the advantage of using MIL algorithm, we also evaluated our algorithm by replacing MIL learning with traditional machine learning algorithm (SVM).
| Method | Accuracy | Subjects/Samples | |
|---|---|---|---|
| MS-MIL (Our algo) |
83.7 | 23/147 | |
| Lucey et.al (previous best) |
80.99 | 20/142 | |
| Ashraf et.al | 68.31 | 20/142 | |
| MS-SVM avg | 70.75 | 23/147 | |
| MS-SVM max | 76.19 | 23/147 |
Localization performance: We also did a qualitative comparison of the pain probabilities per frame predicted by our algorithm through comparison with PSPI index. The PSPI score is used to indicate the amount of pain in each frame and is based on the intensities of 4 action units. One example is shown in Fig.6, where the red colour indicates scores returned by our algorithm and black is the normalized PSPI index. Videos for four cases are shown in Fig.1 (on the top).
 |
|---|
Conclusion: This work proposes a novel approach for classifying and localizing pain in videos. Our algorithm builds upon the limitations of previous approaches by combining multiple segment based representation with robust weakly supervised learning approaches. Our algorithm achieves state of the art results (as of now) on the UNBC MC-Master pain dataset on the task of pain classification in video using video level labellings.
Refrences:
1. Lucey et. al., PAINFUL DATA: The UNBC-McMaster Shoulder Pain Expression Archive Database, FG’11.
2. Sikka et.al, Exploring Bag of Words Architectures for Facial Expression Domain, ECCV’12 Workshop- What’s in the Face.
3. Viola et.al, Multiple Instance Boosting for Object Detection, NIPS'06.
4. Lucey et. Al., Improving pain recognition through better utilization of temporal information, ICASP’08.