
This web site has been restored for historical purposes. Many members of the Machine Perception Laboratory have moved on to exciting new opportunities at Apple, Inc. Unfortunately, INC can only now offer limited support for locating and restoring articles referenced outside of the main MP Lab web site. You may use the Contact Form for reporting broken links and missing articles. We will do our best to locate them from the MP Lab archives.
Databases
IR Marks video data set

The IR Marks video data set is a face motion data set of three video sequences. Prior to filming the three sequences, several points were drawn on the subject’s face using an infrared marking pen. Each video sequence was filmed simultaneously using 4 visible-light cameras (in which the drawn points are not visible) and 3 infrared-sensitive (IR) cameras (in which the drawn points are visible).
For several frames in each sequence, the point locations in all three IR cameras were hand-labeled in order to obtain the groundtruth 3D locations of each of the points. The data set includes the groundtruth 3D locations of these points, as well as their groundtruth 2D locations in the images from the main visible-light camera. Click here for more info
The MPLab GENKI Database

The MPLab GENKI Database is an expanding database of images containing faces spanning a wide range of illumination conditions, geographical locations, personal identity, and ethnicity. The database of images is divided into overlapping subsets, each with its own labels and descriptions. For example, the GENKI-4K subset contains 4000 face images labeled as either “smiling” or “non-smiling” by human coders. The pose of the faces is approximately frontal as determined by our automatic face detector. The GENKI-SZSL subset contains 3500 images containing faces. They are labeled for the face location and size. The images are available for public use. Instructions on downloading.
RUFACS1 (Rochester/UCSD FacialActionCodingSystem Database 1)
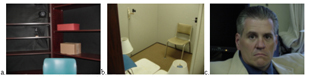
Data collection set up. a. The frontal camera was mounted in a bookshelf above the interrogator’s head. b. Two side view cameras were wall-mounted. A fourth camera was mounted under the interrogator’s chair. c. Interrogators were retired members of the police and FBI, including this county sherrif
The RU-FACS-1 database (short for Rutgers and UCSD FACS database) is being collected by Mark Frank at Rutgers University as part of a collaboration with the Machine perception lab to automate FACS. This database consists of spontaneous facial expressions from multiple views, with ground truth FACS codes provided by two facial expression experts. The data collection equipment, environment, and paradigm were designed with advice from machine vision consultant Yaser Yacoob and facial behavior consultant Paul Ekman. The system records synchronized digital video from 4 Point Grey Dragonfly video cameras and writes directly to RAID.
Subjects participated in a false opinion paradigm in which they were randomly assigned to either lie or tell the truth about their opinion on an issue about which the person has indicated strong feelings (e.g., Frank & Ekman, 1997; 2004). The subject attempts to convince an interviewer he or she is telling the truth. Interviewers are current and former members of the police and FBI. The participants are informed ahead of time of the following pay-offs: (1) If they tell the truth and are believed, they will receive $10; (2) If they lie and are believed they will receive $50; (3) If they are not believed regardless whether they are lying or telling the truth, they are told that they will receive no money and will have to fill out a long boring questionnaire. This paradigm reliably generates many different expressions in a short period of time, which is key for collecting data for training computer vision systems. The paradigm involves natural interaction with another person and does not make the subject aware that the emphasis of the study is on his or her facial expression.
We have collected data from 100 subjects, 2.5 minutes each. This database constitutes a significant contribution towards the 400-800 minute database recommended in the feasibility study for fully automating FACS. To date we have human FACS coded the upper faces of 20% the subjects, which is now available for release. We are on target for finishing the coding by the end of June, and to complete the machine based scoring by the end of the project in 8/31/04.
ORATOR (Expressive Speech Database)
collected by Holger Quast

The following downloadable package contains the wave soundfiles, evaluations, and descriptions of the Orator speech database.
Download: ORATOR (Expressive Speech Database)
For this purpose, 145 spoken versions of the same 8-sentence monologue were recorded:
(1) In der Vergangenheit ist schon einiges an guter Vorarbeit geleistet worden.
(2) Die Ziele, die wir jetzt verfolgen, sind die gleichen und müssen auch auf die gleiche Weise behandelt werden.
(3) Unsere Aufgabe ist nun, noch einmal die Zeiteinteilung durchzusehen.
(4) Sie überprüfen dann das Weitere.
(5) Bitte notieren Sie die Punkte, die Sie heraussuchen, und tragen Sie uns diese vor!
(6) Wir erledigen alles Andere.
(7) Glauben Sie, dass Sie das schaffen?
(8) Gut!
13 professional actors were asked to interpret this text in different social situations producing a total of 117 samples. 14 non-actors spoke the monologue in their natural register yielding the remaining 28 recordings. 20 non-German evaluators listened to these samples and rated their affective content. For this evaluation, sentence 2 of the above monologue was used. 5 additional sentences were included to validate the scores.
The Orator database consists of the following directories and files:
- Readme.pdf
- Audio\complete monologues\1.wav … 145.wav – The 145 recorded monologues. Format is the original DAT 48kHz mono pcm wav.
- Audio\evaluated sentences\1_2.wav … 150_2.wav – The 150 evaluated sentences (sentence 2 of the monologue + 5 extra-samples; for instance, file 23_2.wav contains the second sentence of recording 23.wav). Resampled to CD-rate 44.1kHz.
- Speakers & Recordings.pdf . – The list of speakers of the 145 recorded monologues. Additionally, for the evaluation, 5 extra-samples were played: two repetitions and three sentences other than #2. These extra-samples are files 146_2.wav … 150_2.wav.
- Evaluation Results.xls – Holds all scores the 20 evaluators attributed to the audio samples in an Excel-sheet. These results should be normalized with respect to mean and variance, see the tech report. Also refer to the report to see which impressions can be recognized in the data.
- Quast MPLab Tech Report 2002.2.pdf – This paper explains the project in detail. Read it to get a better understanding of what the data looks like, motivation, signal processing, pattern recognition, and results of the work.
TULIPS1 (Audiovisual Database)
compiled by Javier R. Movellan
The following downloadable package contains the files and description necessary to use the Tulips1 Audiovisual database.
Download: TULIPS1 (Audiovisual Database)
Tulips 1.0 is a small Audiovisual database of 12 subjects saying the first 4 digits in English. Subjects are undergraduate students from the Cognitive Science Program at UCSD. The database was compiled at Javier R. Movellan’s laboratory at the Department of Cognitive Science, UCSD. If you use these data for your research please refer to it as the “TULIPS1 database, (Movellan, 1995)”.
Movellan J. R. (1995) Visual Speech Recognition with Stochastic Networks. in G. Tesauro, D. Toruetzky, & T. Leen (eds.) Advances in Neural Information Processing Systems, Vol 7, MIT Pess, Cambridge.
BEV1 Dataset

The BEV1 Dataset is a resource for those who wish to begin exploring the visual world available to infants and robots, and seeking to answer questions about the wide array of representations learnable without any teacher, and without any informative preexisting knowledge of the world.