This web site has been restored for historical purposes. Many members of the Machine Perception Laboratory have moved on to exciting new opportunities at Apple, Inc. Unfortunately, INC can only now offer limited support for locating and restoring articles referenced outside of the main MP Lab web site. You may use the Contact Form for reporting broken links and missing articles. We will do our best to locate them from the MP Lab archives.
Auto FACS Coding
Principal Investigators: Marian Stewart Bartlett ** Gwen Littlewort ** Javier Movellan ** Mark S. Frank
Fully automated facial action coding
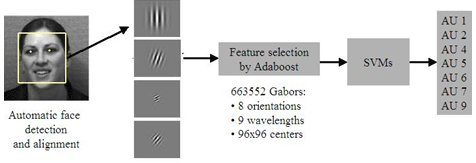
The output of the face detector is fed directly to the facial expression analysis system (see Figure 1). First the face image is passed through a bank of Gabor filters at 8 orientations and 9 scales (2-32 pixels/cycle at 0.5 octave steps). The filterbank representations are then channeled to a statistical classifier to code the image in terms of a set of expression dimensions. We conducted a comparison of classifiers, including support vector machines (SVM’s), Adaboost (Freund & Shapire, 1996), and Linear Discriminant Analysis (Littlewort et al., in press, Bartlett et al., 2003). SVM’s were found to be very effective for classifying facial expressions. Recent research at our lab has demonstrated that both speed and accuracy are enhanced by performing feature selection on the Gabor filters prior to classification (e.g. Bartlett et al., 2003). This approach employs Adaboost for feature selection prior to classification by SVM’s. Adaboost sequentially selects the feature that gives the most information about classification given the features that have been already selected. Adaboost was more effective than other feature selection techniques such as PCA.
a. Results on the DFAT-504 dataset
We developed a system for fully automatic facial action coding of a subset of FACS. This prototype system recognizes all eighteen upper face AU’s (1,2,4,5,6,7 and 9) and is 100% automated. Face images are detected and aligned automatically in the video frames and sent directly to the recognition system. The system was trained on Cohn and Kanade’s DFAT-504 dataset (Kanade, Cohn, & Tian, 2000). This is a dataset of video sequences of university students posing facial expressions. In addition to being labeled for basic emotion, the dataset was coded for FACS scores by two certified FACS coders. There were 313 sequences from 90 subjects, with 1 to 6 emotions per subject. All faces in this dataset were successfully detected by the automatic face tracking system. The automatically detected faces were then passed to the expression analysis system
(As shown in Figure 1).
Seven support vector machines, one for each AU, were trained to detect the presence of a given AU, regardless of whether it occurred alone or in combination with other AU’s. The expression recognition system was trained on the last frame of each sequence, which contained the highest magnitude of the target expression (AU peak). Negative examples consisted of all peak frames that did not contain the target AU, plus 313 neutral images consisting of the first frame of each sequence. A nonlinear radial basis function kernel was employed. Generalization to new subjects was tested using leave-one-out cross-validation (Tukey, 1951). The results are shown in Table 1.
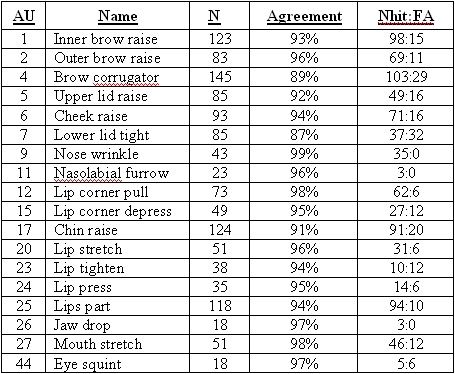
N:Total number of examples of each AU, including combinations containing that AU. Agreement: Percent agreement with Human FACS codes (positive and negative examples classed correctly).
Nhit:FA: Raw number of hits and false alarms, where the number of negative test samples was 626-N.
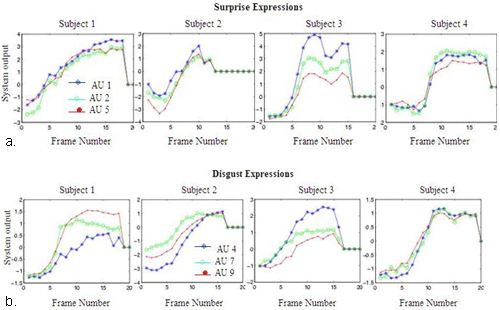
System outputs for full image sequences are shown in Figure 2. These are results for test image sequences, which are sequences not used for training.
The system obtained a mean of 93.6% agreement with human FACS labels for fully automatic recognition of 18 upper facial actions. This is an exciting result, as performance rates are equal to or better than other systems tested on this dataset that employed manual registration. (Tian, Kanade & Cohn, 2001; Kapoor, Qi, & Picard, 2003). Kapoor et al. obtained 81.2% correct on this dataset, using hand marked pupil positions for alignment. Tian et al. obtained a similar level of performance to ours, but hand-marked a set of feature points in neutral expression images immediately preceding each movement. The high performance rate obtained by our system is the result of many years of systematic comparisons investigating which image features (representations) are most effective (Bartlett et al., 1999, Donato et al., 1999), which classifiers are most effective (Littlewort et al., 2004), optimal resolution and spatial frequency (Donato et al., 1999; Littlewort et al., submitted), feature selection techniques (Littlewort et al., submitted), and comparing flow-based to texture-based recognition (Bartlett et al., 1999, Donato et al., 1999).
b. Preliminary results on the RU-FACS-1 dataset.
The UCSD team has just received digital video and FACS codes for the first 20 subjects of the RU-FACS-1 dataset from Rutgers. We are presently testing fully automatic FACS recognition in the continuous video stream using the system described above. Preliminary results based on 1 subject show a mean agreement rate of 88.7% between the automated system and the human FACS codes for the four actions with sufficient data to test (AU’s 1, 2, 6, and 7). Here ‘agreement’ is the percent of frames above or below threshold in accordance with the human codes. In the coming months, we will train AU detectors directly on the spontaneous expression samples from Rutgers as the data becomes available.
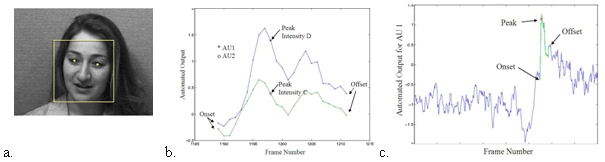
We are presently testing fully automatic FACS recognition in the continuous video stream. Faces images were automatically detected. Alignment in the 2D plane was then refined using automatically detected eye locations. The resulting images were then ported to the AU detectors trained on the DFAT-504 database. The figure below shows example system outputs for a video sequence that contains an AU 1 and AU 2. Preliminary results based on 1 subject show a mean agreement rate of 88.7% between the automated system and the human FACS codes for the four actions with sufficient data to test (AU’s 1, 2, 6, and 7). (Results by action are AU 1, 87.3% for AU2, 92.4% for AU 6, and 86.4% for AU 7).Here ‘agreement’ is the percent of frames above or below threshold in accordance with the human codes. In the coming months, we will train AU detectors directly on the spontaneous expression samples from Rutgers as the data becomes available.